(kudos to Ramzy for being great company while solving this challenge, love you bud)
After solving discoParty—the challenge recommended to me by keymoon, I asked for other suggestions
from keymoon in hopes of triggering the same dopamine rush from solving a hard CTF challenge.
“…but this is kinda misc-ish chall”, he said.
He referred to this challenge as misc-ish, which at the time discouraged me a little as
I was chasing something more “realistic”, but man was I mistaken about how good this one is :)
Enjoy this read, as we’ll talk about a lot of things.
The Challenge
The challenge is an authentication scheme. You log into an auth provider (called Zer0TP),
and the latter hands you tokens to give back to access your account on the original website.
Looking at the code, we see the client (the one using Zer0TP as an auth provider) giving the flag under this condition:
1
@app.route("/")
2
defhome():
3
if'username'notin flask.session:
4
return flask.redirect("/login")
5
6
# You can also manage admin users if you're using
7
# the enterprise plan (1337 USD/month)
8
r = requests.get(f"http://{ZER0TP_HOST}:{ZER0TP_PORT}/api/is_admin",
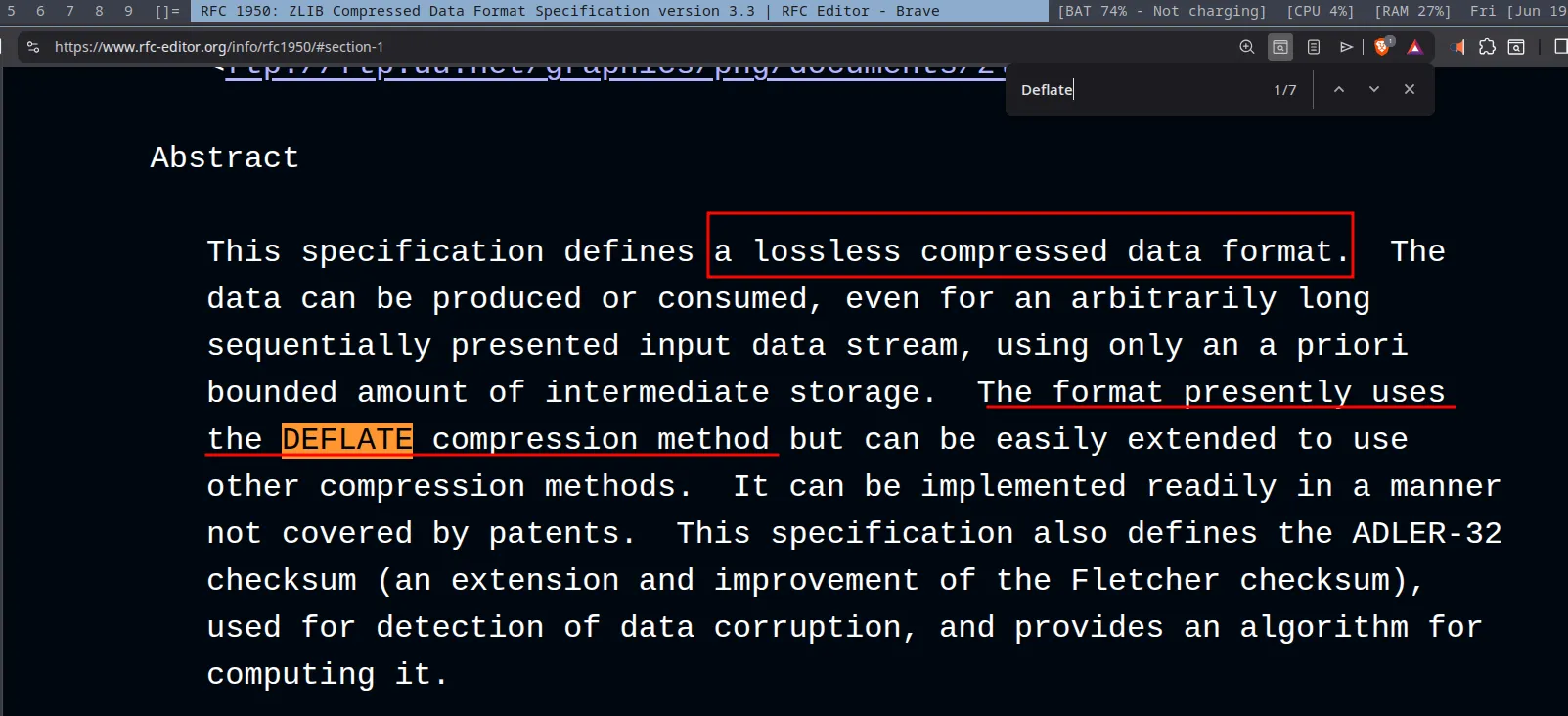
In other words, zlib is a data format (think JSON for us web normies) that holds compressed
data, i.e., data that was once big in size and is now small in size. The RFC states
that zlib uses “DEFLATE” to compress this data into a smaller form.
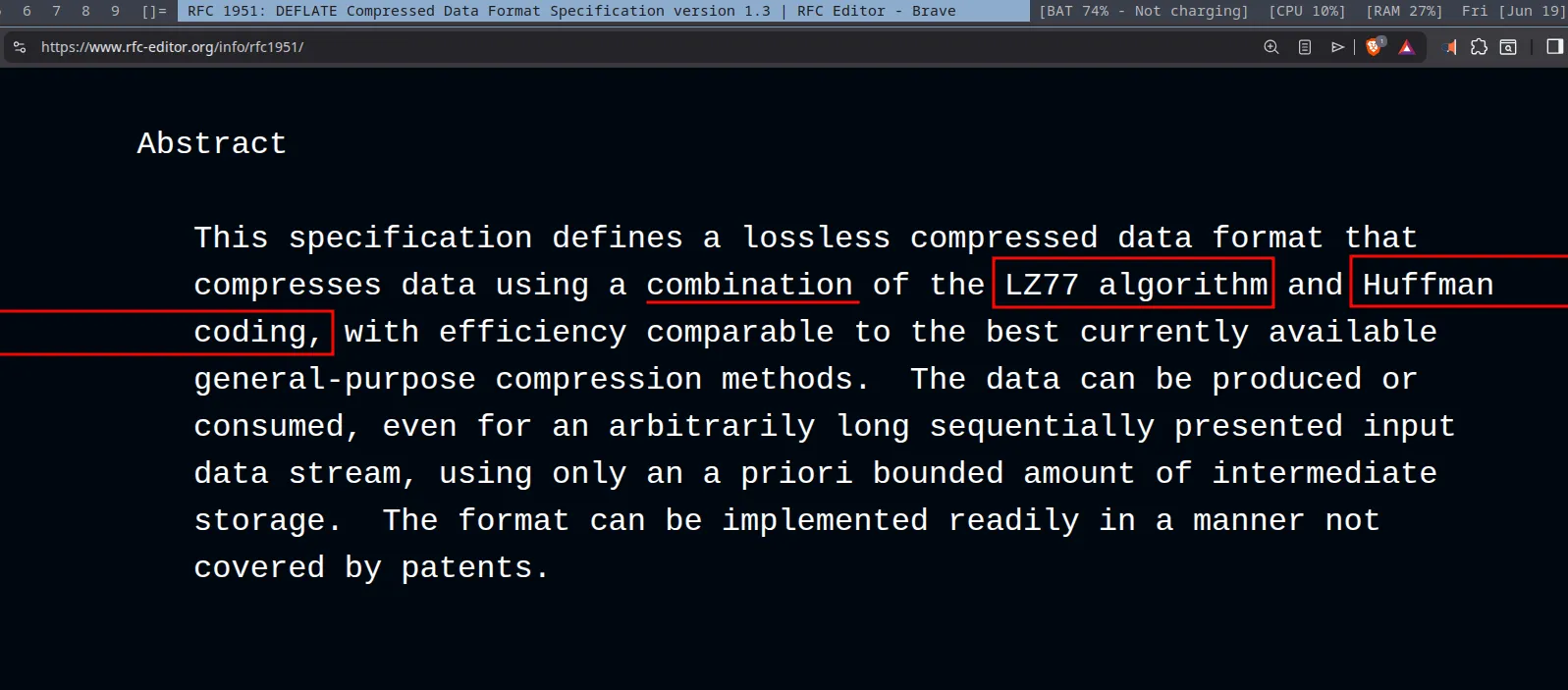
Turns out DEFLATE is the engine that produces the compressed data, and zlib is a wrapper
around this compressed data. If you read the compression algorithm details, you will notice
how it uses LZSS (a variant of LZ77) as well as Huffman coding to compress data.
The info for either is beyond the scope of this writeup, but you should check this video
which excellently explains the whole process.
In short, though, assume we have ‘foo baar baaz’ as our input, the compressor does the following:
Compresses the input once using LZSS by creating backreferences. Instead of the substring ‘baa’ appearing
twice, we only write it once, and its second occurrence becomes a <length, distance> pair, i.e.:
1
foo baar baaz --> foo baar <3,5>z
Jump 5 positions back and write 3 characters, effectively ‘baa’.
Takes the output of LZSS and encodes each symbol (literals, lengths and distances) based on frequencies (Huffman coding):
If a symbol is more frequent, give it a short bit length. For example, if ‘a’ recurs more often,
then we give it 1 bit (say 0) to encode it; ‘z’ recurs less often, so we give it 3 bits (say 101), and so on.
3. Block Types (BTYPE)
The DEFLATE bitstream is split into data blocks; each block contains data that is
either compressed or uncompressed (you can embed uncompressed data too in a DEFLATE stream).
To know which type we’re dealing with, we inspect the 1st byte of DEFLATE:
1
Bit: 0 1 2 3 ...
2
+---+---+---+=============================+
3
|BFF| BTYPE| ... compressed payload ... |
4
+---+---+---+=============================+
BTYPE can be:
‘00’ indicating raw uncompressed payload to come
‘01’ indicating a fixed Huffman coding
‘10’ indicating a dynamic Huffman coding
‘11’ is reserved, but never actually used.
You might be wondering: “What is the difference between fixed and dynamic Huffman coding?”
Dynamic VS. Fixed Huffman Coding
In our worked example previously, I mentioned how symbols were encoded using the intuitive
approach of giving frequent symbols shorter bit-lengths and vice versa. It turns out the
mapping between symbol and code can be dynamically or statically assigned. Here’s how:
If BTYPE = ‘01’, the decompressor holds a hardcoded lookup table for each Huffman
code and its corresponding symbol.
If BTYPE = ‘10’, the lookup table is encoded in the block to tell the decompressor
how to decode each encoded symbol.
What’s interesting is that info about the payload is encoded in the header, namely:
HLIT and HDIST include information about how many <length, distance> pairs exist.
If your input triggers a backreference, HLIT will be greater than 0, otherwise it’s 0.
Do you see the oracle?
If we force dynamic Huffman coding (and we can, because we control the username), then
the 1st byte of the DEFLATE header can be inspected to see if a substring of our username
recurs in the secret or not!
Note: Zlib is a wrapper around DEFLATE, and the 1st byte of DEFLATE is the 3rd byte of Zlib
1
0 1
2
+---+---+=====================+---+---+---+---+
3
|CMF|FLG|...compressed data...| ADLER32 |
4
+---+---+=====================+---+---+---+---+
Recovering The Secret
Following our logic train, it should be noted that ideally, the only backreference we
generate is the one matching a given prefix + a character from the secret. After some digging
through the RFC, I found out that a minimum of 3 similar bytes will trigger a backreference.
Our goal then becomes to give a username in which every substring of length 3 occurs exactly once.
That way, when we add a prefix + secret[0], noise is reduced and HLIT is more readily inspected.
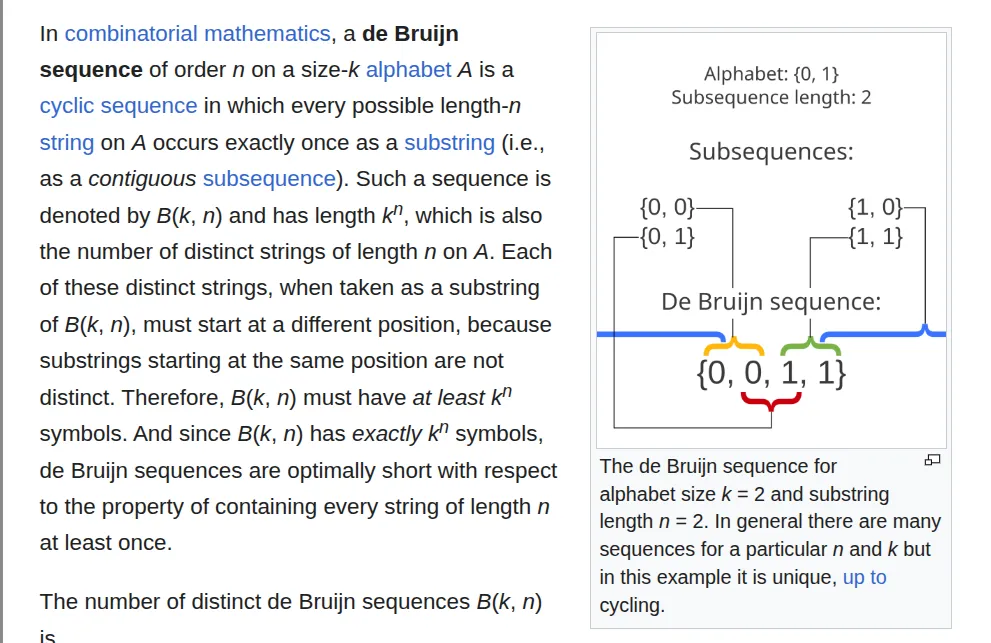
Where can we find such a sequence, though? Well, after some digging, I found the De Bruijn sequence.
Good. We have everything to solve our 2nd goal. Again, the goal is to recover the secret from this code:
1
import os
2
import zlib
3
import base64
4
import signal
5
import hashlib
6
7
secret = base64.b64encode(os.urandom(12))
8
assertlen(secret) ==16
9
10
whileTrue:
11
username =input().encode()
12
assert4<=len(username) <=50
13
print(zlib.compress(username + secret)[:8])
I won’t cover the code in detail, and I trust you can understand it well :)
step2.py
1
import os, sys
2
import zlib
3
import base64
4
import hashlib
5
6
secret = base64.b64encode(os.urandom(12))
7
# secret = b'pcVeloMX8EfvwaoO'
8
assert(len(secret) ==16)
9
10
# username = input('> ').encode()
11
# k = 4 and n = 3 (4**3=64)
12
# I picked this alphabet so it doesn't overlap with the secret base64 alphabet
I could’ve studied the format of the block header more meticulously, but it was
at this moment that I got lazy and dynamically learned which bits, among the 64 bits
of the zlib compression output, were stable, and which fluctuated.
The vibe coded script is this:
1
import os
2
import zlib
3
import random
4
5
# --- Challenge Parameters ---
6
secret =b'pcVeloMX8EfvwaoO'# Or a dummy secret of the same length
print("\n[+] Conclusion: This space is small enough to brute-force locally almost instantly.")
Turns out, for 100_000 tries, we had 4 million possible combinations. In linear time,
and for a modern computer, that is a walk in the park.
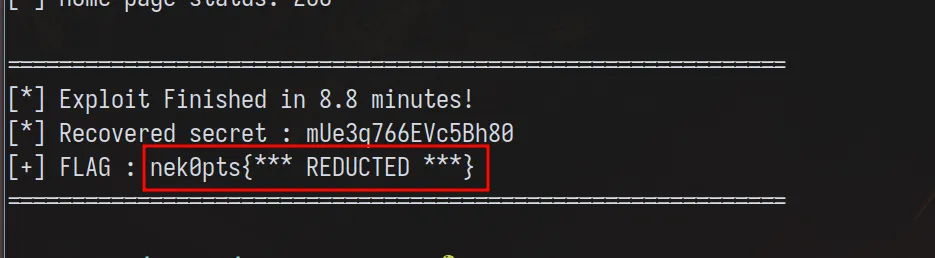
Knowing which bits changed and which stayed the same, I vibe coded a solve script
that got the flag like this:
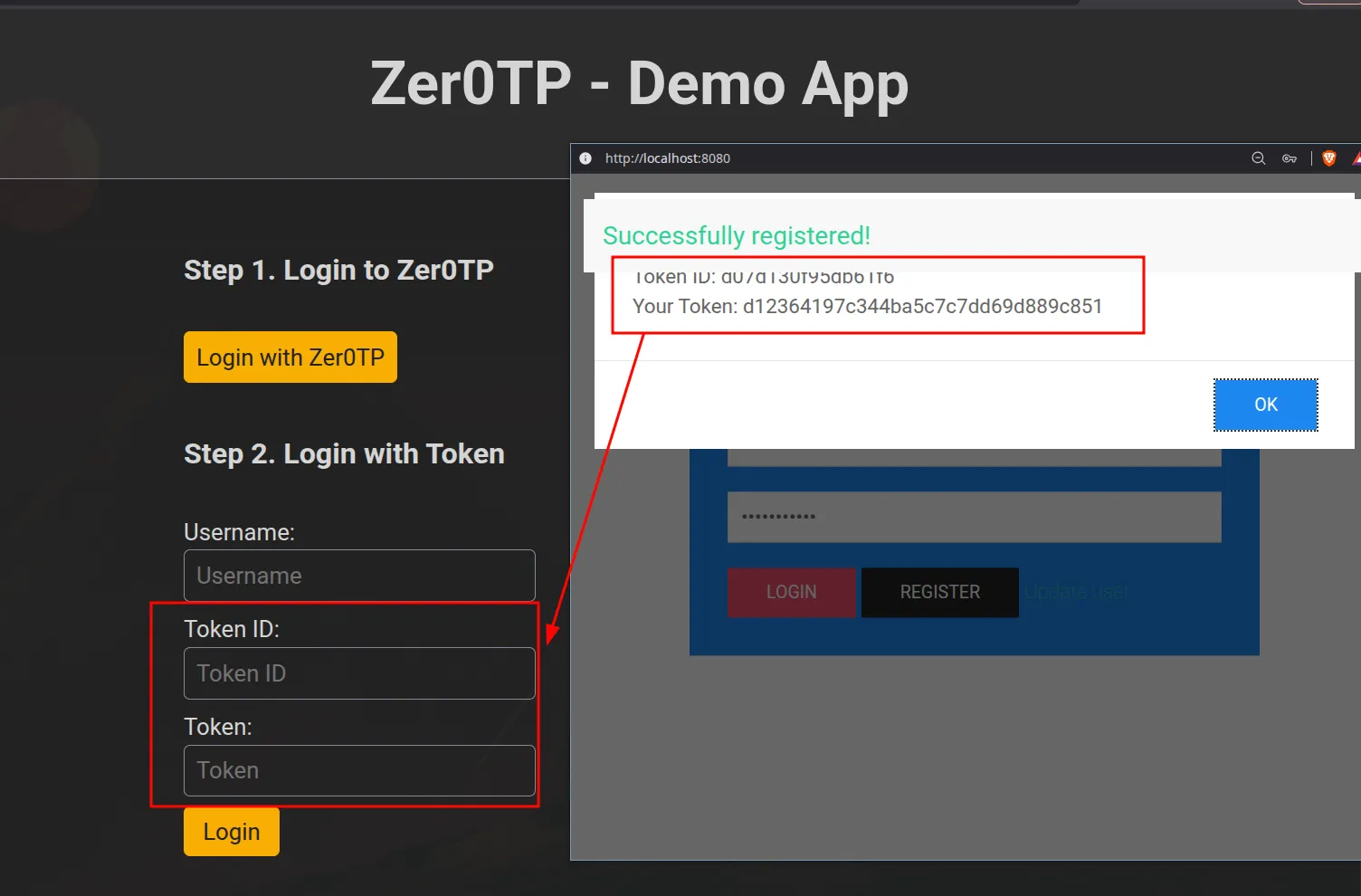
Registers a baseline account on the Zer0TP service to establish an initial, valid session state.
Executes a side-channel brute-force loop to leak the 16-byte secret byte-by-byte. We continuously rename the user with a crafted username incorporating a De Bruijn sequence. By analyzing how changes to the input affect the Huffman tree metadata structures (the HLIT variations reflected in the token hashes), the loop acts as an oracle to confirm correct character guesses.
Cleans up the account state by renaming the user back to the original baseline username (baseusr) once the full 16-byte secret has been successfully recovered.
Escalates privileges to administrator by submitting the leaked secret token directly to the /api/set_admin endpoint.
Authenticates against the third-party application using the escalated session tokens, follows the subsequent redirect, and extracts the target flag (nek0pts{...}) from the application home page.
exploit.py
1
import os
2
import sys
3
import zlib
4
import hashlib
5
import time
6
import requests
7
import re
8
9
# ==========================================
10
# 0. CONFIGURATION
11
# ==========================================
12
ZER0TP_URL="http://localhost:8080"# Zer0TP service
print(f"curl -X GET '{ZER0TP_URL}/api/is_admin?username={current_name.decode()}'")
And there we go~ We got the flag :)
Key Takeaways
The Danger of Mixed-Trust Compression: Combining user-controlled data (the username) and sensitive secrets (the auth token) within the same compression context opens the door to side-channel leakage. This is the exact underlying mechanism behind famous web vulnerabilities like CRIME and BREACH.
Tree Metadata as an Oracle: In dynamic Huffman coding (BTYPE = 10), the compressor must send the shape of its trees in the block header via fields like HLIT. Because these field sizes fluctuate based on whether a duplicate string was found, an attacker can use the header size itself as an oracle to confirm or deny character guesses.
De Bruijn Sequences for Noise Reduction: When testing for string matching via compression, using a De Bruijn sequence ensures that every possible n-gram of a certain length occurs exactly once. This eliminates accidental self-overlapping matches within your own payload, isolating the side-channel to only look for matches against the secret.
Empirical Bit-Masking over Math Deficit: When confronted with complex, bit-aligned cryptographic or structural puzzles, mapping the output state empirically using an entropy analysis script can reveal structural invariants. Here, discovering that only a fraction of the 64-bit space actually fluctuated drastically collapsed the MD5 brute-force complexity down to linear, instantly crackable scales.